BrandWise Metrics System — How Brand Performance in AI Is Measured
6 metrics for evaluating brand representation in ChatGPT, Claude, and Gemini: Visibility, Relevance, Positioning Match, Usefulness, Top of Mind, and Consideration. 0–100 scale with evidence quotes.
Why You Need a Metrics System
When a user asks ChatGPT "which service should I choose for X," the model's response shapes brand perception. But how do you measure how well AI represents your brand? The mere fact of a mention tells you nothing about quality — what matters is where the brand appears, whether the description matches your positioning, and whether the response helps the user take action.
BrandWise solves this with 6 specialized metrics, each measuring a distinct aspect of brand representation in AI model responses.
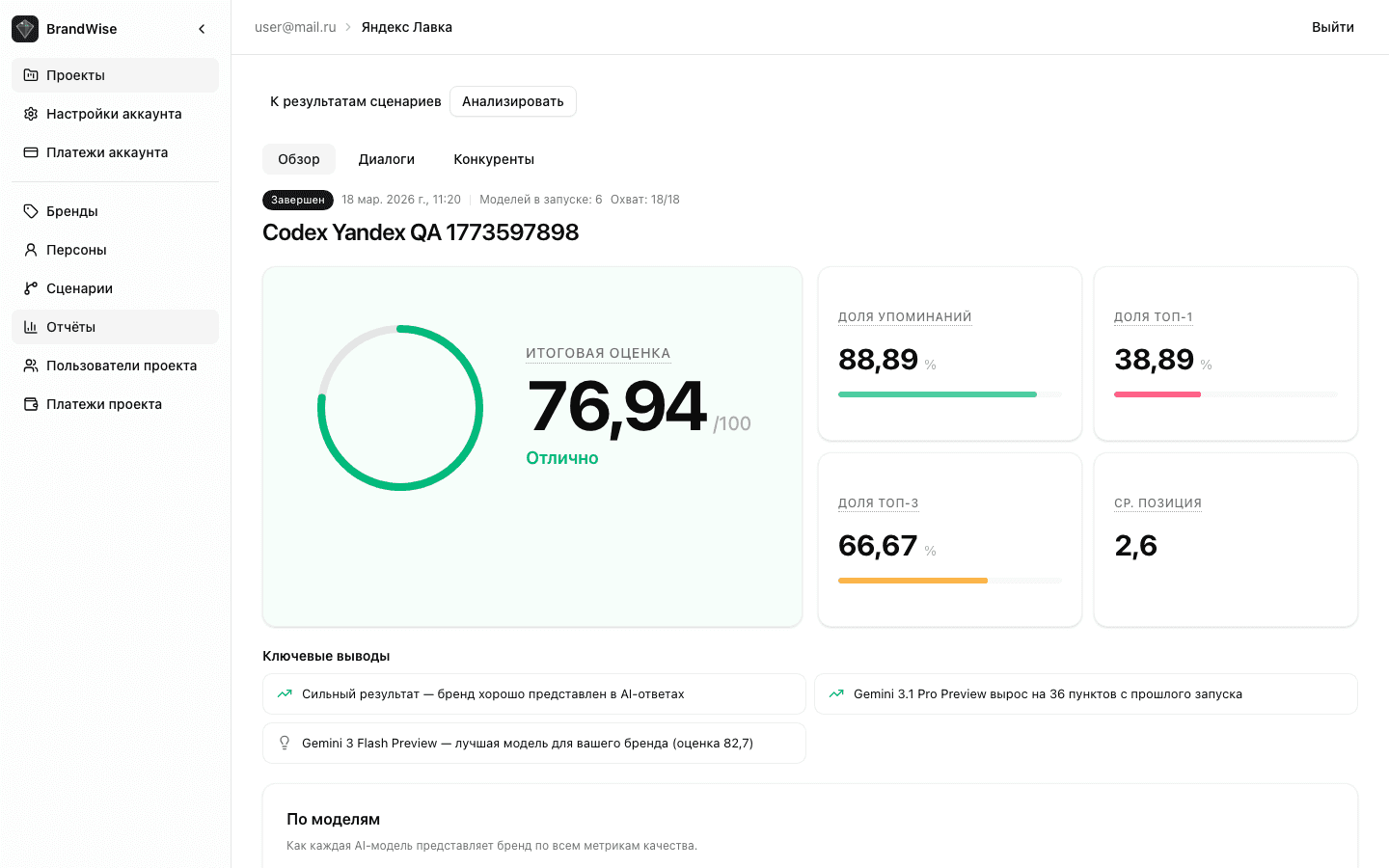
Six Brand Evaluation Metrics
All metrics are scored on a unified 0–100 scale and grouped into three categories:
Brand Strength
| Metric | What It Measures |
|---|---|
| Visibility | How prominently the brand appears — position and detail level |
| Top of Mind | Whether the model recalls the brand before competitors |
Representation Quality
| Metric | What It Measures |
|---|---|
| Relevance | Whether the brand mention matches the user's query |
| Positioning Match | Whether the response reflects your intended brand positioning |
| Usefulness | Whether the mention helps the user make a decision |
Competitive Position
| Metric | What It Measures |
|---|---|
| Top of Mind | Brand position relative to competitors |
| Consideration | Whether the brand makes the recommendation shortlist |
Evidence Quotes — The Proof Behind Every Score
Every score is backed by evidence quotes — verbatim excerpts from the model's response. These are not summaries or interpretations, but exact substrings of text that justify the score.
For example, if Visibility = 85, you'll see the exact fragments where the model mentions your brand in a top list with multiple supporting arguments. This ensures full transparency: you can always verify why a particular score was assigned.
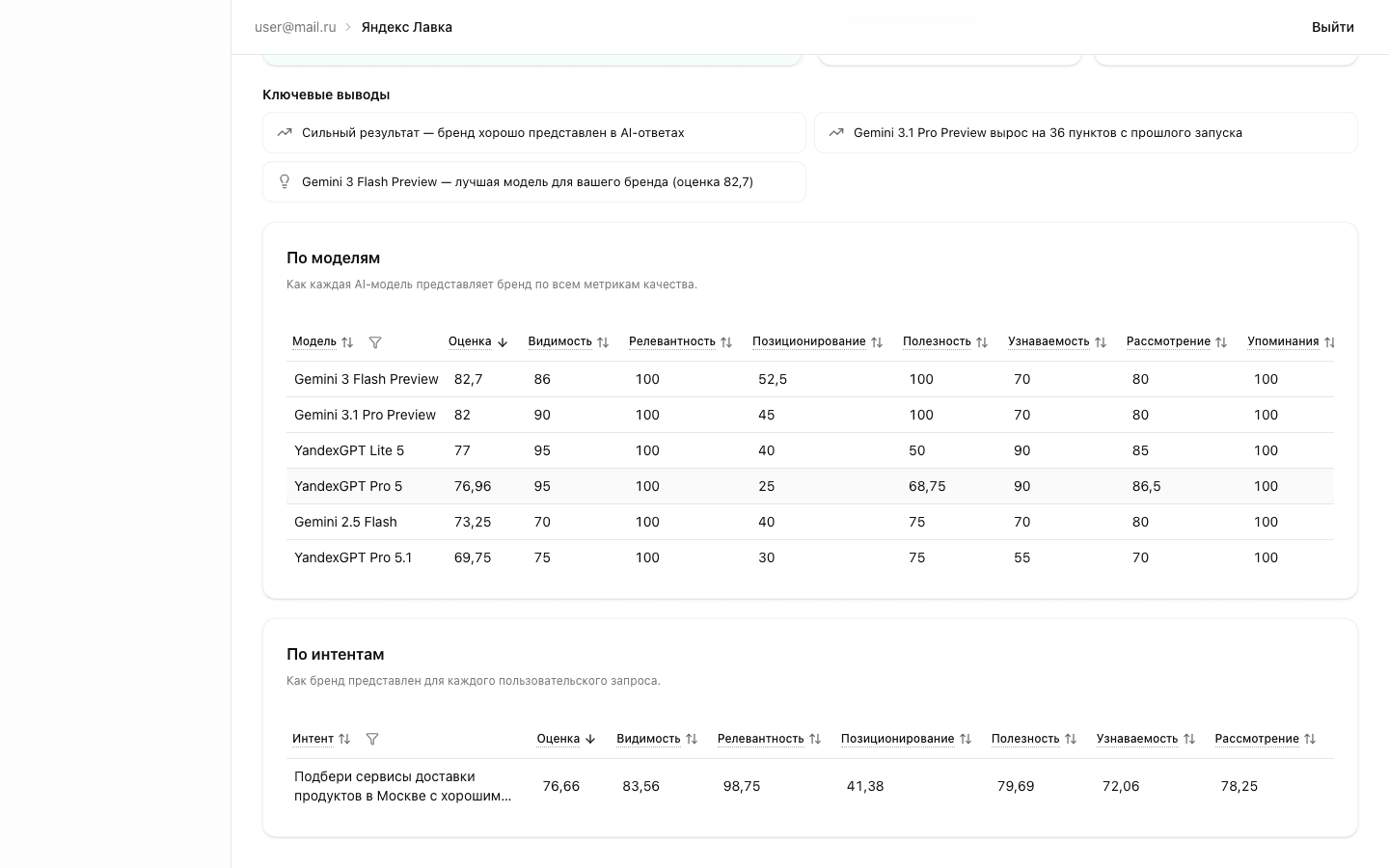
Overall Score
The Overall Score is a weighted average of applicable metrics for each model response:
| Metric | Weight |
|---|---|
| Top of Mind | 30% |
| Consideration | 25% |
| Visibility | 20% |
| Relevance | 10% |
| Positioning Match | 10% |
| Usefulness | 5% |
Only applicable metrics are included. Visibility, Top of Mind, and Consideration count toward the Overall Score only for organic context — when the user didn't mention the brand in their query.
Additionally, mention context affects the score: if the brand is mentioned negatively or with caveats, a global multiplier is applied to all metrics except Visibility (Positive = ×1.0, Mixed = ×0.5, Negative = ×0.2). This means a negative brand mention significantly reduces the Overall Score.
Learn more about derived metrics in Derived and Aggregate Metrics.
Interpretation Scale
| Range | Level | What It Means |
|---|---|---|
| 70–100 | Excellent | Brand is represented exceptionally — high position, relevant description, strong arguments |
| 50–69 | Good | Solid representation with room for improvement |
| 40–49 | Average | Moderate representation — brand is mentioned but without clear advantages |
| 0–39 | Weak | Poor representation — brand is either absent or described superficially |
Query Context Classification
Every model response is classified by context type:
- Organic — the user didn't mention the brand in their query (e.g., "which CRM should I choose"). This is the most valuable context: it shows whether the model recalls your brand on its own.
- Brand Prompted — the brand was explicitly mentioned in the query (e.g., "tell me about BrandWise"). Visibility, Top of Mind, and Consideration are excluded from the Overall Score for this context.
- Unclear — ambiguous context that couldn't be classified definitively.
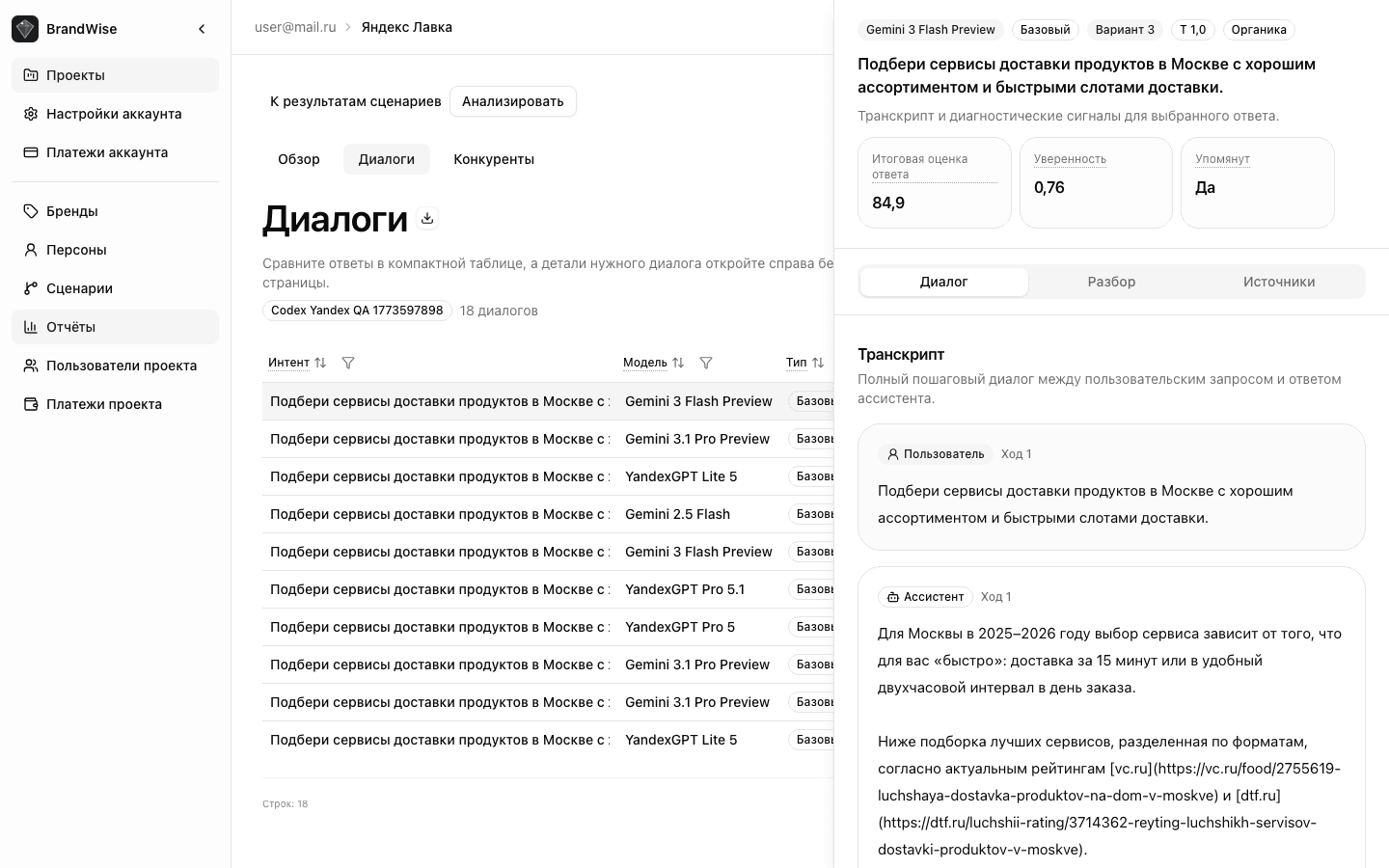
Data Quality Flags
The system automatically checks every evaluation for quality:
- prompt_injection_suspected — injection patterns detected in the dialog (attempts to override instructions)
- evidence_mismatch — quotes not found in the original model response text
These flags help filter unreliable results and ensure high-quality analytics.
What's Next
Explore each metric in detail:
- Visibility — Brand Visibility
- Relevance — Mention Relevance
- Positioning Match — Positioning Alignment
- Usefulness — Recommendation Usefulness
- Top of Mind — Brand Recall Priority
- Consideration — Shortlist Inclusion
- Derived and Aggregate Metrics
Ready to start? Create a project and run your first evaluation to see the metrics in action.
Running a Brand Evaluation — Statuses, Checks, and Resuming Runs
How to run a scenario evaluation in BrandWise: pre-launch balance checks, run status lifecycle, resuming stopped runs, and email notifications.
Visibility — Brand Visibility in AI Model Responses
The Visibility metric in BrandWise: how brand prominence in ChatGPT, Claude, and Gemini responses is measured. Formula, components, interpretation examples.